The Excel_plan() – batch scans using a spreadsheet#
Use a spreadsheet as a multi-sample batch scan tool.
We’ll need a spreadsheet with some things to be done
and a plan that will read that spreadsheet and act on it.
This plan will:
[x] use an Excel spreadsheet (for starters)
[x] read a table from the spreadsheet file
[x] take a single action from each row in the table
[x] decide action based on a specific named column in the table
[x] report all columns as metadata for the action
[x] ignore empty rows
[ ] ignore any data outside of the table boundaries
Since the actions and parameters (args & kwargs) will be
different in every implementation, this may prove difficult
to generalize.given a spreadsheet (named sample_example.xlsx)
with content as shown in the next figure:
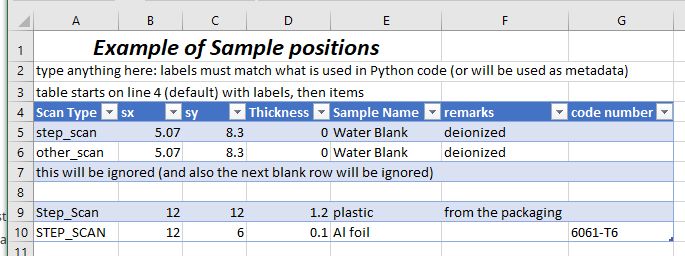
Tip: Place the column labels on the fourth row of the spreadsheet, starting in the first column. The actions start on the next row. The first blank row indicates the end of the command table within the spreadsheet. Use as many columns as you need, one column per argument.
Here’s the demo, starting with the bluesky setup.
# Import matplotlib and put it in interactive mode.
%matplotlib notebook
import matplotlib.pyplot as plt
plt.ion()
import pathlib
import databroker
cat = databroker.temp()
from bluesky import RunEngine
import bluesky.plans as bp
import bluesky.plan_stubs as bps
from bluesky.callbacks.best_effort import BestEffortCallback
from bluesky import SupplementalData
from bluesky.simulators import summarize_plan
from bluesky.suspenders import SuspendFloor
from ophyd.sim import motor1, motor2, motor3, SynGauss
import apstools.devices as APS_devices
import apstools.utils as APS_utils
RE = RunEngine({})
RE.subscribe(cat.v1.insert)
RE.subscribe(BestEffortCallback())
RE.preprocessors.append(SupplementalData())
shutter = APS_devices.SimulatedApsPssShutterWithStatus(name="shutter")
watch_for_shutter_close = SuspendFloor(shutter.pss_state, 1)
noisy_det = SynGauss('noisy_det', motor1, 'motor1', center=0, Imax=1,
noise='uniform', sigma=0.9, noise_multiplier=0.1, labels={'detectors'})
noisy_det.kind = "hinted"
Excel plan and infrastructure#
def beforeExcelPlan():
"""things to be done at the start of every Excel plan"""
yield from bps.mv(
shutter, "open", # for example
)
def afterExcelPlan():
"""things to be done at the end of every Excel plan"""
yield from bps.mv(
shutter, "close", # for example
motor1, 0, # park the motors
motor2, 0,
motor3, 0,
)
def common_step_scan(pos_X, pos_Y, thickness, scan_title, md={}):
"""
run a step scan over a common range at given sample position
"""
yield from bps.mv(
motor2, pos_X,
motor3, pos_Y,
)
md[motor2.name] = motor2.position
md[motor3.name] = motor3.position
md["shutter"] = shutter.state
for k, v in md.items():
print(f"{k}: {v}")
yield from bps.install_suspender(watch_for_shutter_close)
yield from bp.scan([noisy_det], motor1, -5, 5, 8, md=md)
yield from bps.remove_suspender(watch_for_shutter_close)
def Excel_plan(xl_file, md={}):
"""
example of reading a list of samples from Excel spreadsheet
USAGE::
summarize_plan(run_Excel_file("sample_example.xlsx"))
RE(run_Excel_file("sample_example.xlsx"))
"""
excel_file = pathlib.Path(xl_file)
assert excel_file.exists()
xl = APS_utils.ExcelDatabaseFileGeneric(str(excel_file))
yield from beforeExcelPlan()
for i, row in enumerate(xl.db.values()):
# print(f"row={row}")
# metadata
# all parameters from this row go into the metadata
# columns names are the keys in the metadata dictionary
# make sure md keys are "clean"
# also provide crossreference to original column names
_md = {APS_utils.cleanupText(k): v for k, v in row.items()}
_md["table_row"] = i+1
_md["Excel_file"] = str(excel_file)
_md["xl_file"] = xl_file
_md["original_keys"] = {APS_utils.cleanupText(k): k for k in row.keys()}
_md.update(md) # overlay with user-supplied metadata
scan_command = (row["Scan Type"] or "").lower()
if scan_command == "step_scan":
yield from common_step_scan(
row["sx"], # label must match cell string EXACTLY
row["sy"],
row["Thickness"],
row["Sample Name"],
# add all input as scan metadata, ensure the keys are clean
md=_md,
)
elif scan_command == "some_other_action":
pass # TODO: suggestion
else:
print(f"no handling for table row {i+1}: {row}")
yield from afterExcelPlan()
summarize_plan(Excel_plan("sample_example.xlsx"))
shutter -> open
motor2 -> 5.07
motor3 -> 8.3
Scan_Type: step_scan
sx: 5.07
sy: 8.3
Thickness: 0
Sample_Name: Water Blank
remarks: deionized
code_number: None
table_row: 1
Excel_file: sample_example.xlsx
xl_file: sample_example.xlsx
original_keys: {'Scan_Type': 'Scan Type', 'sx': 'sx', 'sy': 'sy', 'Thickness': 'Thickness', 'Sample_Name': 'Sample Name', 'remarks': 'remarks', 'code_number': 'code number'}
motor2: 0
motor3: 0
shutter: close
=================================== Open Run ===================================
motor1 -> -5.0
Read ['noisy_det', 'motor1']
motor1 -> -3.571428571428571
Read ['noisy_det', 'motor1']
motor1 -> -2.142857142857143
Read ['noisy_det', 'motor1']
motor1 -> -0.7142857142857144
Read ['noisy_det', 'motor1']
motor1 -> 0.7142857142857144
Read ['noisy_det', 'motor1']
motor1 -> 2.1428571428571432
Read ['noisy_det', 'motor1']
motor1 -> 3.571428571428571
Read ['noisy_det', 'motor1']
motor1 -> 5.0
Read ['noisy_det', 'motor1']
================================== Close Run ===================================
no handling for table row 2: OrderedDict([('Scan Type', 'other_scan'), ('sx', 5.07), ('sy', 8.3), ('Thickness', 0), ('Sample Name', 'Water Blank'), ('remarks', 'deionized'), ('code number', None)])
no handling for table row 3: OrderedDict([('Scan Type', 'this will be ignored (and also the next blank row will be ignored)'), ('sx', None), ('sy', None), ('Thickness', None), ('Sample Name', None), ('remarks', None), ('code number', None)])
shutter -> close
motor1 -> 0
motor2 -> 0
motor3 -> 0
RE(Excel_plan("sample_example.xlsx"))
Scan_Type: step_scan
sx: 5.07
sy: 8.3
Thickness: 0
Sample_Name: Water Blank
remarks: deionized
code_number: None
table_row: 1
Excel_file: sample_example.xlsx
xl_file: sample_example.xlsx
original_keys: {'Scan_Type': 'Scan Type', 'sx': 'sx', 'sy': 'sy', 'Thickness': 'Thickness', 'Sample_Name': 'Sample Name', 'remarks': 'remarks', 'code_number': 'code number'}
motor2: 5.07
motor3: 8.3
shutter: open
Transient Scan ID: 1 Time: 2022-07-06 00:27:29
Persistent Unique Scan ID: 'a6ea8a82-aff2-4621-a197-1a3bca524e51'
New stream: 'primary'
+-----------+------------+------------+------------+
| seq_num | time | motor1 | noisy_det |
+-----------+------------+------------+------------+
| 1 | 00:27:29.7 | -5.000 | 0.017 |
| 2 | 00:27:29.7 | -3.571 | 0.021 |
| 3 | 00:27:29.7 | -2.143 | 0.115 |
| 4 | 00:27:29.7 | -0.714 | 0.658 |
| 5 | 00:27:29.7 | 0.714 | 0.697 |
| 6 | 00:27:29.7 | 2.143 | 0.155 |
| 7 | 00:27:29.7 | 3.571 | -0.086 |
| 8 | 00:27:29.7 | 5.000 | 0.089 |
+-----------+------------+------------+------------+
generator scan ['a6ea8a82'] (scan num: 1)
no handling for table row 2: OrderedDict([('Scan Type', 'other_scan'), ('sx', 5.07), ('sy', 8.3), ('Thickness', 0), ('Sample Name', 'Water Blank'), ('remarks', 'deionized'), ('code number', None)])
no handling for table row 3: OrderedDict([('Scan Type', 'this will be ignored (and also the next blank row will be ignored)'), ('sx', None), ('sy', None), ('Thickness', None), ('Sample Name', None), ('remarks', None), ('code number', None)])
('a6ea8a82-aff2-4621-a197-1a3bca524e51',)
Show what was collected by accessing the most recent run from the catalog.
run = cat[-1]
run
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|