Export bluesky data to CSV#
Export bluesky experiment data from databroker to CSV files. Each data stream is written to its own file.
As a bonus, it is shown how to write all of a run’s data to a single JSON file.
First, identify the experiment data to be exported. Show what catalogs are available.
[1]:
import databroker
list(databroker.catalog)
[1]:
['class_2021_03', 'class_example_data']
Pick from the class_example_data catalog.
[2]:
cat = databroker.catalog["class_example_data"]
len(cat)
[2]:
59
Just show a few of the most recent runs.
[3]:
from apstools.utils import *
listruns(num=9)
catalog: class_example_data
scan_id time plan_name detectors
0 90 2021-03-06 14:16:41 scan [noisy]
1 89 2021-03-06 14:15:35 scan [noisy]
2 88 2021-03-06 14:14:45 scan [noisy]
3 87 2021-03-06 14:13:44 scan [noisy]
4 86 2021-03-06 14:10:46 rel_scan [noisy]
5 85 2021-03-06 14:10:43 rel_scan [noisy]
6 84 2021-03-06 14:10:37 rel_scan [noisy]
7 83 2021-03-06 14:10:19 rel_scan [noisy]
8 82 2021-03-03 10:01:32 count [adsimdet]
Check what is in #85.
[4]:
run = cat[85]
run
[4]:
BlueskyRun
uid='b4e4cbbb-a4b1-4146-aea5-ba8bc7ad7b76'
exit_status='success'
2021-03-06 14:10:43.261 -- 2021-03-06 14:10:46.260
Streams:
* primary
* baseline
Look at the data in the primary stream. That’s the experiment data.
[5]:
ds = run.primary.read()
ds
[5]:
<xarray.Dataset>
Dimensions: (time: 23)
Coordinates:
* time (time) float64 1.615e+09 1.615e+09 ... 1.615e+09 1.615e+09
Data variables:
m1 (time) float64 0.915 0.918 0.922 ... 0.988 0.992 0.995
m1_user_setpoint (time) float64 0.9146 0.9183 0.922 ... 0.988 0.9917 0.9954
noisy (time) float64 1.464e+03 1.767e+03 ... 1.674e+03 1.494e+03- time: 23
- time(time)float641.615e+09 1.615e+09 ... 1.615e+09
array([1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09, 1.615061e+09])
- m1(time)float640.915 0.918 0.922 ... 0.992 0.995
- object :
- m1
array([0.915, 0.918, 0.922, 0.926, 0.929, 0.933, 0.937, 0.94 , 0.944, 0.948, 0.951, 0.955, 0.959, 0.962, 0.966, 0.97 , 0.973, 0.977, 0.981, 0.984, 0.988, 0.992, 0.995]) - m1_user_setpoint(time)float640.9146 0.9183 ... 0.9917 0.9954
- object :
- m1
array([0.91461872, 0.91828974, 0.92196077, 0.92563179, 0.92930282, 0.93297385, 0.93664487, 0.9403159 , 0.94398692, 0.94765795, 0.95132897, 0.955 , 0.95867103, 0.96234205, 0.96601308, 0.9696841 , 0.97335513, 0.97702615, 0.98069718, 0.98436821, 0.98803923, 0.99171026, 0.99538128]) - noisy(time)float641.464e+03 1.767e+03 ... 1.494e+03
- object :
- noisy
array([ 1463.92124654, 1766.77807072, 2094.50450468, 2798.32521782, 3305.86485887, 4534.74655493, 6865.43764098, 9149.30587732, 15753.27851951, 33071.73105762, 56524.5928228 , 94208.51149034, 60687.14648988, 33271.44458305, 16008.77693897, 9858.98556194, 6690.43920525, 4799.07549787, 3380.49964564, 2709.74517481, 2142.78312427, 1674.13140299, 1494.37780746])
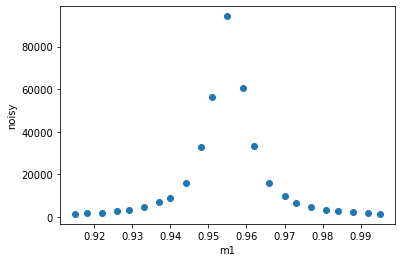
Plot it.
[6]:
ds.plot.scatter("m1", "noisy")
[6]:
<matplotlib.collections.PathCollection at 0x1e79ecff1c0>
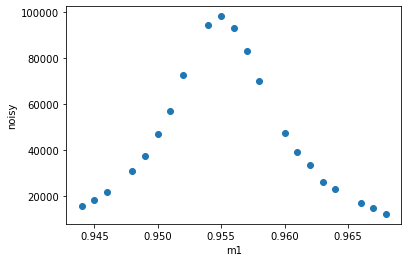
Assuming #90 has the same type of scan, plot it.
[7]:
cat[90].primary.read().plot.scatter("m1", "noisy")
[7]:
<matplotlib.collections.PathCollection at 0x1e79fdf6dc0>
Export one run to CSV#
Make a function to do this, then call it with the run. The function should export all data streams and the run’s metadata. Each to a separate CSV file.
Starting with a catalog instance,
cat, pick arunbyscan_id(oruid).Look at the stream names, the run’s experimental data is in the
primarystream.The stream data is obtained in an xarray Dataset:
ds = run.primary.read()The stream data can be converted to CSV (by first converting to a pandas DataFrame):
ds.to_pandas().to_csv()Write the CSV to a file.
The run’s metadata is already a dictionary (making it difficult to render as CSV). The
csvpackage has a special writer for dictionaries.
[8]:
import csv
from xarray.core.dataset import Dataset as xarray_Dataset
from pandas import DataFrame as pandas_DataFrame
def export_run(run):
"Save all the run information to text files."
scan_id = run.metadata["start"]["scan_id"]
def export_data(data, scan_id, label, prefix="run"):
with open(f"{prefix}-{scan_id}-{label}.csv", "w", newline="\n") as f:
if isinstance(data, dict):
writer = csv.DictWriter(f, data.keys())
writer.writeheader()
writer.writerow(data)
elif isinstance(data, xarray_Dataset):
f.write(data.to_pandas().to_csv())
elif isinstance(data, pandas_DataFrame):
f.write(data.to_csv())
print(f"wrote file: {f.name}")
export_data(run.metadata, scan_id, "metadata")
for stream_name in run:
ds = getattr(run, stream_name).read()
if stream_name == "baseline":
ds = ds.to_pandas().transpose()
export_data(ds, scan_id, stream_name)
export_run(run)
wrote file: run-85-metadata.csv
wrote file: run-85-primary.csv
wrote file: run-85-baseline.csv
Search for runs by time#
Since a search by scan_id` might not be unique, we hope to resolve that by restricting the time span for a search. Here’s how to search by a time span.
[9]:
time_span = databroker.queries.TimeRange(since="2021-03-06 14:00", until="2021-03-06 16:00")
runs = cat.search(time_span)
len(cat), len(runs)
[9]:
(59, 8)
Export a list of runs#
Search the catalog by time and scan_id for a list of runs. Call the export_run() function on each run. We’ll look for #70 - #84 using the range(70, 86) function. But, since we have a time restriction, only some of the scans will be written.
The result of cat.search(query) (where query is a dictionary of search terms) is another catalog with runs matching the search terms. This result can be searched again and again as needed. The dictionary can use mongoquery as shown here: {'scan_id': {'$in': scan_id_list}}
Here, a time span is selected along with a list of scan IDs. The time span is searched first, since any scan_id might not be unique in the catalog. (assumption: A scan_id might be unique within the time span.) The result is a catalog of scans from the list but also within the time span.
[10]:
def export_runs(scan_id_list, since=None, until=None):
runs = cat
# first by date since scan_id might not be unique for all times
if since is not None:
runs = runs.search(databroker.queries.TimeRange(since=since))
if until is not None:
runs = runs.search(databroker.queries.TimeRange(until=until))
# now, search by scan_id (in the supplied list)
runs = runs.search({'scan_id': {'$in': scan_id_list}})
for uid in runs:
export_run(runs[uid])
export_runs(range(70, 86), since="2021-03-06 14:00")
wrote file: run-83-metadata.csv
wrote file: run-83-primary.csv
wrote file: run-83-baseline.csv
wrote file: run-84-metadata.csv
wrote file: run-84-primary.csv
wrote file: run-84-baseline.csv
wrote file: run-85-metadata.csv
wrote file: run-85-primary.csv
wrote file: run-85-baseline.csv
Export run to JSON file#
A Python dictionary can be written to JSON (its contents can be expressed in JSON. There are a few notable problems, such as None values.) Here, a dictionary (data) is built with the different parts of a run (metadata, streams). Then data is written to a single file.
[12]:
import json
def export_json(run):
"""Export all data from a run to a JSON file."""
scan_id = run.metadata["start"]["scan_id"]
data = {"metadata": run.metadata}
for stream_name in list(run): # get ALL the streams
# such as data["primary"] = run.primary.read().to_dict()
data[stream_name] = getattr(run, stream_name).read().to_dict()
with open(f"run_{scan_id}.json", "w", newline="\n") as f:
f.write(json.dumps(data, indent=2))
print(f"wrote file {f.name}")
export_json(run)
wrote file run_85.json